Methodische Qualitätssicherung in der klinischen Krebsforschung
In der klinischen Krebsforschung entscheidet nicht allein die Menge der erhobenen Daten über den Studienerfolg, sondern deren Qualität, Konsistenz und Regelkonformität. Genau hier setzt ein methodisch aufgebautes Clinical Data Warehouse an, das Daten, Bedeutung und Auswertung konsequent voneinander trennt.
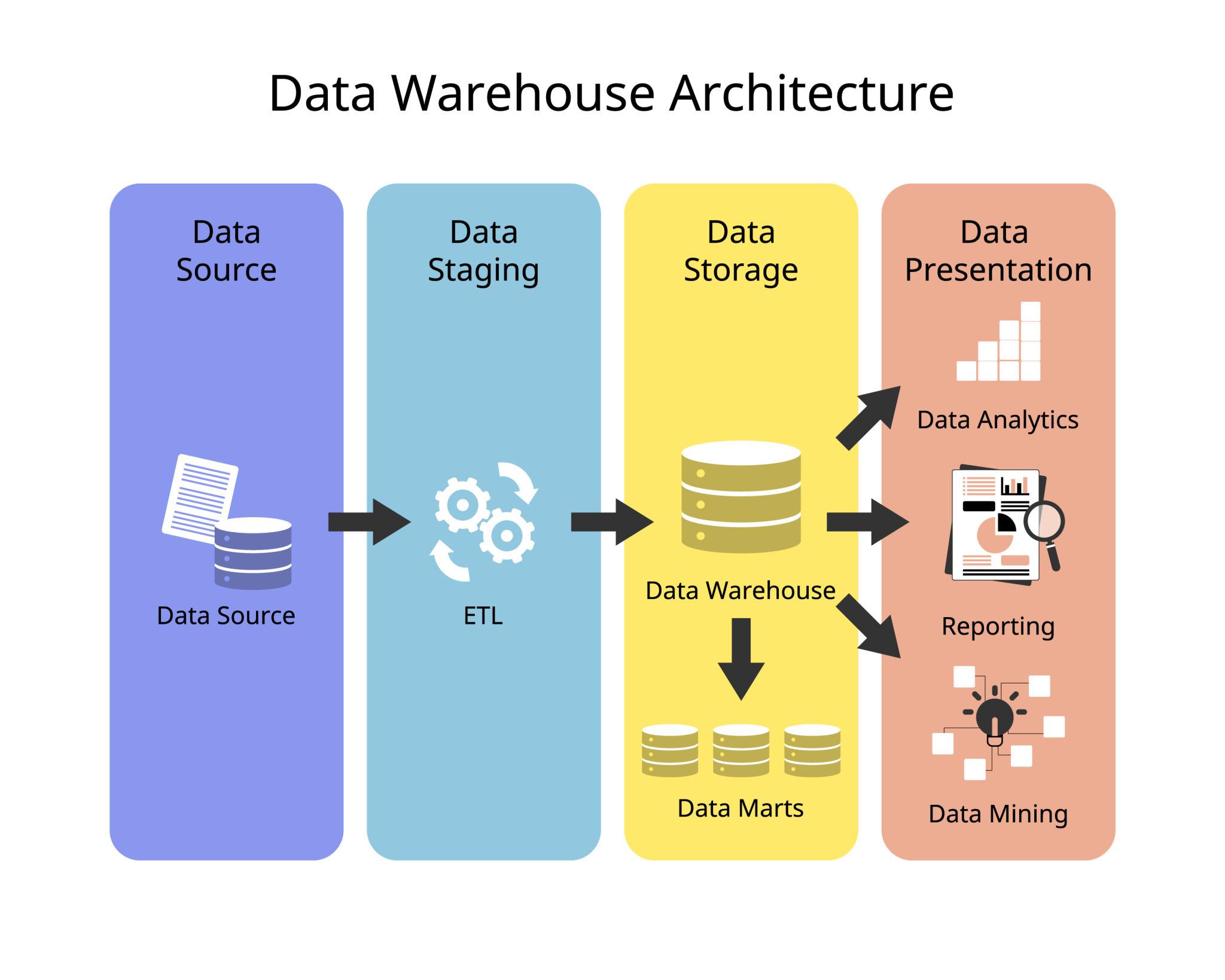
Kurzüberblick: Semantische Datenpipeline
Die Architektur folgt einem klaren, leicht nachvollziehbaren Prinzip:
ETL (raw data)
↓
Core (Dim / Fact)
↓
DWH API (atomar)
↓
Mart (fachliche Bedeutung)
↓
SSRS / Export
Jede Stufe hat eine klar definierte Aufgabe. Dadurch bleibt die Datenbasis stabil, während fachliche Regeln flexibel angepasst werden können.
Was dieser Ansatz leistet – auf einen Blick
- Bewusste Trennung von Datenerhebung, Regelableitung und Auswertung
- Explizite Modellierung von Patienten- und Query-Ereignissen
- Atomare Zugriffsschicht (DWH API) statt direkter Zugriffe auf Rohdaten
- Nachvollziehbare Regeln statt impliziter Statistiklogik
- Messbare Dokumentationsqualität auf Patienten- und Zentrumsebene
- Auditfähige, reproduzierbare Datenbasis
- Deskriptive BI als Visualisierung – nicht als Wahrheitsquelle
Ziel: Center Health Status Report

Das zentrale Ziel ist ein Center Health Status Report, der nicht interpretiert, sondern sichtbar macht:
- Wie vollständig dokumentieren Studienzentren ihre Patientendaten?
- Gibt es zeitliche Inkonsistenzen im Studienverlauf?
- Werden definierte Studienregeln eingehalten?
- Wie stabil und konsistent ist die Dokumentation über die Zeit?
- Wie performant werden Queries bearbeitet?
Damit wird Qualität nicht nur geprüft, sondern systematisch beobachtbar.
Architekturprinzip
-
Core (Dim / Fact)
Rohe, historisch korrekte Studiendaten ohne fachliche Interpretation. -
DWH API (atomar)
Kontrollierte Zugriffsschicht mit klarer Körnung (Patient, Query, Event, Zentrum). Keine Filter, keine Zeitfenster, keine Business-Logik. -
Mart
Fachliche Bedeutung: Statusdefinitionen, Zeitfenster (BETWEEN), Aggregationen (WHERE,HAVING), Qualitäts- und Aging-Regeln. -
SSRS / Export
Reine Visualisierung und Datenbereitstellung. Keine fachliche Logik.
Die Komplexität liegt bewusst in Views und expliziten Regeln, nicht in tausendzeiligen Export- oder Report-Skripten.
Clinical Data Mining statt klassischer BI
In diesem Kontext bedeutet Data Mining nicht Vorhersage oder Blackbox-Modelle, sondern:
- Erkennen von Dokumentationslücken
- Aufdecken zeitlicher Inkonsistenzen
- Identifikation von Regelverletzungen
- Vergleich von Zentren über stabile Qualitätsmetriken
Die Statistik folgt später – auf einer belastbaren, geprüften Datenbasis.
Vergleich: Klassische CDISC-/R-Pipeline vs. DWH-basierte Semantic Pipeline
| Aspekt | CDISC / R / SAS Pipeline | DWH + Semantic Layer + BI |
|---|---|---|
| Datenmodell | Analyseorientiert, flache Analyse-Datasets (ADaM) | Ereignis- und regelbasiert (Dim / Fact / Event) |
| Zielsetzung | Statistische Auswertung, Hypothesentests | Qualitätssicherung, Konsistenz, Regelkonformität |
| Patientenebene | Vorhanden, aber meist aggregiert | Explizit modelliert bis auf Ereignisebene |
| Zentrumsebene | Begrenzt, oft sekundär | Zentraler Analysefokus (Center Health) |
| Regellogik | Implizit im R-/SAS-Code | Explizit in SQL-Views (Mart Layer) |
| Statusdefinitionen | Kontextabhängig, skriptgebunden | Zentral definiert, versionierbar |
| Reproduzierbarkeit | Abhängig von Skriptversionen | Strukturell gegeben durch Schichtenmodell |
| Auditfähigkeit | Gut für Statistik, begrenzt für Datenqualität | Hoch – Datenherkunft und Regeln nachvollziehbar |
| Drill-down | Analyseabhängig | Standardisiert bis Patient- und Query-Ebene |
| Rolle der BI | Nicht vorgesehen | Reine Visualisierung, keine Logik |
| Zeitpunkt im Studienverlauf | Spät (nach Daten-Lock) | Früh und kontinuierlich |
| Stärken | Statistische Validität | Frühe Qualitätskontrolle, operative Steuerung |
Einordnung:
Beide Ansätze sind nicht konkurrierend, sondern komplementär.
Die DWH-basierte Semantic Pipeline sichert Datenqualität und Regelkonformität
während der Studie – die CDISC-/R-Pipeline nutzt diese stabile Basis
für die finale statistische Auswertung.
Weiterführende Literatur
-
The Data Warehouse Toolkit (3rd Edition)
Ralph Kimball – das Standardwerk für Dimensional Modeling.
Zum Buch auf Amazon -
Analytics Engineering with SQL and dbt
Rui Pedro Machado – moderne Modellierung und semantische Layer.
Zum Buch auf Amazon -
SQL Antipatterns
Bill Karwin – warum große SQL-Monolithen scheitern.
Zum Buch auf Amazon
Fazit
Clinical Data Mining, Data Warehousing und deskriptive BI sind keine konkurrierenden Konzepte, sondern klar getrennte Bausteine einer sauberen, semantischen Pipeline.
Die Statistik kommt zum Schluss.
Die Qualitätssicherung kommt zuerst.