Können operative Studiendaten mehr sein als reine Studiendokumentation?
In klinischen Studien entstehen täglich große Mengen operativer Daten. Patienten werden gescreent, randomisiert, behandelt und über Jahre nachbeobachtet. Gleichzeitig werden Visiten dokumentiert, Queries bearbeitet, unerwünschte Ereignisse erfasst sowie klinische Beobachtungen wie ECOG oder FACT-B erhoben.
Diese Daten sind unverzichtbar für die Durchführung einer klinischen Studie. Ihr Informationsgehalt bleibt jedoch häufig auf einzelne Formulare oder Tabellen beschränkt. Für sich allein beantworten sie weder die Frage, wo sich ein Patient aktuell im Studienprozess befindet, noch wie sein aktueller klinischer Zustand ist.
Die spannende Frage lautet daher:
Wie lassen sich operative Studiendaten reproduzierbar in aussagekräftige Informationen überführen?
Das Clinical Data Warehouse als Grundlage
Der erste Schritt besteht in der Integration sämtlicher operativer Studiendaten in ein Clinical Data Warehouse.
Hier werden Informationen aus unterschiedlichen Studiendomänen harmonisiert, qualitätsgesichert und in einem gemeinsamen Datenmodell zusammengeführt. Dadurch entsteht eine konsistente Datenbasis, auf der weitere analytische Modelle aufgebaut werden können.
Auf Grundlage dieser integrierten Daten wird anschließend eine Patient State Machine erzeugt. Sie beschreibt reproduzierbar den longitudinalen Studienverlauf jedes Patienten und bildet den Kern des weiteren Informationsmodells.
Process first, AI second
Bevor Prognosemodelle, Clustering-Verfahren oder KI-Methoden sinnvoll eingesetzt werden können, muss der zugrunde liegende Studienprozess reproduzierbar modelliert werden.
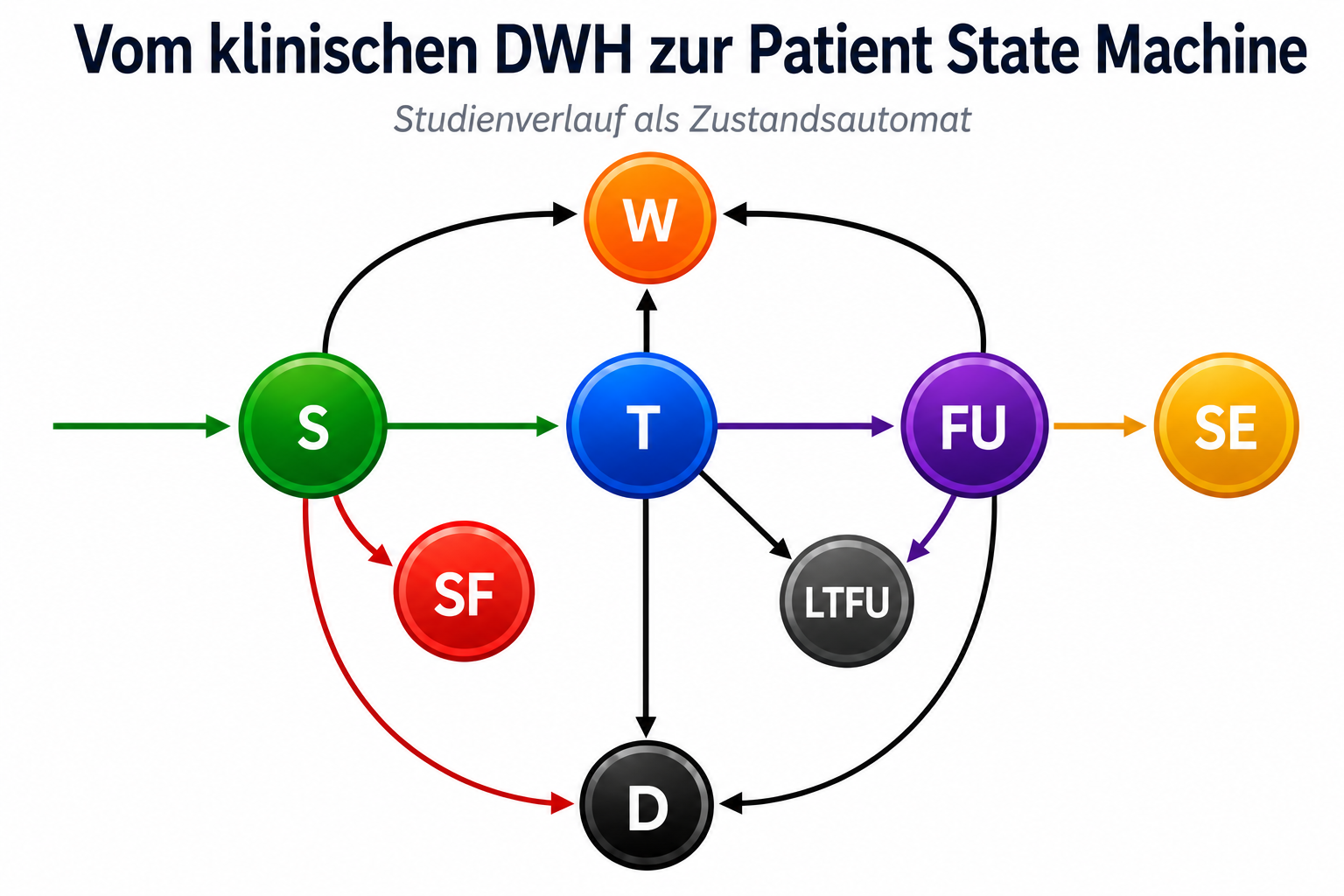
Die Grundlage hierfür bildet die Patient State Machine. Sie leitet sich konzeptionell aus der Automatentheorie ab und beschreibt den Studienverlauf als endlichen Zustandsautomaten. Jeder Patient bewegt sich dabei durch eine begrenzte Menge klinisch interpretierbarer Prozesszustände – vom Studieneinschluss über Therapie- und Follow-up-Phasen bis hin zum Studienende.
Typische Zustände sind beispielsweise:
- Screening (S)
- Therapy (T)
- Follow-up (FU)
- Pending
- Study End (SE)
Die Übergänge zwischen diesen Zuständen werden durch dokumentierte Ereignisse aus dem eCRF ausgelöst, beispielsweise durch Informed Consent, Randomisierung, Therapiestart, letzte Medikamentengabe oder Studienende. Dadurch entsteht ein gerichtetes Prozessmodell, das für jeden Patienten nachvollziehbar abbildet, wo er sich im Studienprozess befindet und wie er dorthin gelangt ist.
Die Patient State Machine bildet damit die Schaltzentrale des gesamten Prozessmodells. Sie liefert den Prozesskontext, auf dem sowohl der Clinical Process Twin als auch der Clinical Digital Twin aufbauen.
Erst auf dieser stabilen und reproduzierbaren Grundlage werden weiterführende Verfahren sinnvoll einsetzbar – etwa Trendanalysen, Clusterverfahren, Vergleiche mit Referenzpopulationen oder KI-basierte Vorhersagemodelle. Ohne ein explizites Prozessmodell wären solche Analysen lediglich Auswertungen fragmentierter Rohdaten. Mit der Patient State Machine erhalten sie einen klinisch interpretierbaren Kontext.
Der Clinical Study Twin
Aus der Patient State Machine entsteht der Clinical Study Twin.
Er stellt das zentrale Informationsmodell einer klinischen Studie dar und vereint zwei unterschiedliche, sich ergänzende Perspektiven auf denselben Patienten.
Operative Studiendaten
(secuTrial)
│
▼
Clinical Data Warehouse
│
▼
Patient State Machine
│
▼
Clinical Study Twin
┌────────┴────────┐
▼ ▼
Clinical Process Twin Clinical Digital Twin
(History & Monitoring) (Current Clinical Snapshot)
│ │
▼ ▼
Studienteam / Monitore Behandelnde Ärzte
Der Clinical Process Twin
Der Clinical Process Twin beschreibt den historischen Studienverlauf eines Patienten.
Er beantwortet unter anderem folgende Fragen:
- Wo befindet sich der Patient aktuell im Studienprozess?
- Welche Prozessphasen wurden bereits durchlaufen?
- Welche Studienmeilensteine stehen an oder sind überfällig?
- Gibt es offene Queries?
- Sind Adverse Events oder Serious Adverse Events dokumentiert?
- Gibt es Hinweise auf Verzögerungen im Studienablauf?
Der Clinical Process Twin dient dem operativen Prozessmonitoring und richtet sich in erster Linie an das Studienteam sowie klinische Monitore.
Er stellt die vollständige Historie des Studienverlaufs bereit und ermöglicht eine kontinuierliche Überwachung der Studiendurchführung.
Der Clinical Digital Twin
Während der Clinical Process Twin den Studienverlauf beschreibt, konzentriert sich der Clinical Digital Twin auf den aktuellen klinischen Zustand des Patienten.
Hierzu werden patientenbezogene Beobachtungen wie beispielsweise
- ECOG
- FACT-B
- Laborparameter
- molekulare Biomarker
- zukünftig kontinuierliche Wearable-Daten
dem aktuellen Prozesszustand des Patienten zugeordnet.
Patient Reported Outcomes (PRO)
Ein besonderer Mehrwert entsteht durch die Einbindung von Patient Reported Outcomes (PRO).
Vom Patienten selbst ausgefüllte Fragebögen werden nicht lediglich im elektronischen Case Report Form (eCRF) gespeichert, sondern automatisiert ausgewertet und in den Clinical Digital Twin integriert.
Dadurch fließen Angaben des Patienten beispielsweise zu
- Lebensqualität
- Fatigue
- Schmerzen
- körperlicher Belastbarkeit
- Symptombelastung
gemeinsam mit objektiven klinischen Beobachtungen in einen strukturierten klinischen Statusbericht ein.
Der Clinical Digital Twin entwickelt sich damit zu einer patientenzentrierten Zusammenfassung des aktuellen Gesundheitszustands.
Der aktuelle klinische Snapshot
Der Clinical Digital Twin beantwortet beispielsweise folgende Fragen:
- Wie ist der aktuelle funktionelle Status des Patienten?
- Wie entwickelt sich die gesundheitsbezogene Lebensqualität?
- Welche Veränderungen zeigen sich innerhalb der aktuellen Therapiephase?
- Wie unterscheiden sich aktuelle Beobachtungen vom Studienbeginn?
- Welche Veränderungen berichtet der Patient selbst?
Der Clinical Digital Twin stellt somit keinen weiteren Monitoringprozess dar, sondern einen aktuellen klinischen Statusbericht, der den behandelnden Arzt bei der Visite unterstützt.
Zwei Perspektiven auf denselben Patienten
Obwohl beide Modelle auf denselben operativen Studiendaten basieren, verfolgen sie unterschiedliche Ziele.
Clinical Process Twin
Frage:
Wo befindet sich der Patient aktuell im Studienprozess?
Zielgruppe:
Studienteam und klinische Monitore
Aufgabe:
- Historie
- Monitoring
- Milestones
- Queries
- Safety
Clinical Digital Twin
Frage:
Wie ist der aktuelle klinische Zustand des Patienten?
Zielgruppe:
Behandelnde Ärztinnen und Ärzte
Aufgabe:
- Aktueller Statusbericht
- ECOG
- FACT-B
- PRO
- Labor
- Biomarker
Reproduzierbare Informationsgewinnung
Der entscheidende Unterschied zu vielen datengetriebenen Ansätzen besteht darin, dass sämtliche Informationen reproduzierbar aus den operativen Studiendaten abgeleitet werden.
Jede Kennzahl, jede Beobachtung und jede Statusinformation lässt sich bis auf die ursprünglichen Studiendaten zurückverfolgen.
Aus fragmentierten operativen Studiendaten entsteht dadurch ein strukturierter Clinical Study Twin, der unterschiedliche Informationsbedürfnisse bedient.
- Studienteam und Monitore erhalten den Clinical Process Twin für das operative Prozessmonitoring.
- Behandelnde Ärztinnen und Ärzte erhalten den Clinical Digital Twin als aktuellen klinischen Statusbericht für die Visite.
Ausblick
Heute basiert der Clinical Digital Twin bereits auf diskreten klinischen Beobachtungen wie ECOG, FACT-B und Patient Reported Outcomes.
Perspektivisch kann dieses Konzept um Laborparameter, molekulare Biomarker sowie kontinuierlich erhobene Wearable-Daten erweitert werden. Dadurch lassen sich künftig auch digitale Biomarker, beispielsweise Aktivitätsprofile oder Hinweise auf Fatigue, in den klinischen Statusbericht integrieren.
Das grundlegende Architekturprinzip bleibt dabei unverändert:
Operative Studiendaten werden reproduzierbar in einen Clinical Study Twin überführt, der sowohl den historischen Studienverlauf als auch den aktuellen klinischen Zustand eines Patienten transparent und nachvollziehbar abbildet.